What the PC Revolution Taught Us About AI
The AI productivity revolution is real. Whether it reaches everyone depends on a question Silicon Valley isn't asking.


In January 1983, a company called Lotus Development Corporation walked onto the floor of Comdex and changed business computing forever. Its product, Lotus 1-2-3, was immediately recognized as something different; faster than anything before it, integrated, elegant. Byte magazine called it “revolutionary instead of evolutionary.” Millions of people would eventually buy IBM PCs largely just to run it.
The price was $495.
That’s roughly $1,600 in today’s dollars. Per seat. For a spreadsheet.
WordStar, the dominant word processor of the era, ran you another $495. dBASE II, the database of choice, was $700. A fully configured business machine with software could easily run $3,500 to $4,000 in 1983 dollars per desk. Companies bought these machines, but they were rationed and shared like capital equipment. I recall working at Paine Webber on Wall Street as an intern in the mid 1980’s and sharing an IBM PC across the entire Commercial Paper team. The spreadsheet lived in finance. The word processor belonged to the executive suite. Most workers never touched any of it.
Here is the thing that gets lost in the often retelling of the PC revolution: the spreadsheet did not transform American business productivity in 1983. The transformation came later in the late 1980s and through the 1990s, and it came not because the software got better, though it did. It came because the hardware got “cheap”. And understanding “why” it got cheap is the key to understanding what AI needs to do next.
Why Technology Before the PC Had to Be Expensive
There is a theory in innovation economics, developed by Clayton Christensen and grounded in earlier work by Henderson and Clark, called the theory of interdependence and modularity. It sounds academic. It is a precise description of why transformative technologies are always expensive at first and what has to happen before they can become cheap.
The theory makes a simple but powerful distinction. A system is interdependent when the components cannot be designed independently of one another. Changing one part requires rethinking others. The interfaces between components are complex, unpredictable, and proprietary. The only way to optimize the whole system is to control all of it. Modularity, by contrast, exists when the interfaces between components are fully specified and standardized when it doesn’t matter who makes a component, as long as it meets the standard.
Interdependence is not a flaw. In the early stages of a technology’s life, when performance is still well below what users need, interdependence is necessary. You cannot squeeze every last bit of performance out of a system if you allow the components to be designed by separate companies optimizing independently with different visions of what to build. The integration tax is worth paying because the performance gains are what matter.
Before the PC, computing was a textbook case of interdependence. IBM’s mainframes and minicomputers were vertically integrated from silicon to software, IBM designed the chips, the operating systems, the storage subsystems, the terminals, and the sales relationship. Every layer was co-engineered together. The result was machines that performed reliably at the frontier of what was possible and that only IBM could build, which meant only IBM could price. An IBM System/370 mainframe was priced anywhere from $1 million to $10 million. Yes, plug compatible systems emerged, but IBM set the standards. Enterprise computing was rationed to the largest organizations precisely because the interdependence that made the technology work also concentrated the pricing power in one place.
The IBM PC of 1981 was IBM’s deliberate break from that model and an accidental act of self-destruction. Under pressure to move fast and hit a $1,500 price point, the PC team at Boca Raton made a series of decisions that ran against everything IBM had ever done. They used off-the-shelf components: an Intel 8088 processor, Microsoft’s operating system, Tandon’s floppy and Seagate’s hard drive, Epson’s printer. Most remarkably, they published the full technical specifications circuit designs, source code and invited third parties to build software and peripherals around it. IBM thought it was building an ecosystem around its platform. It was opening the interfaces that would eventually make it irrelevant.
The one layer IBM held back was the BIOS, the low-level firmware sitting between the hardware and the operating system. That proprietary BIOS was IBM’s last attempt to maintain an interdependent interface in an otherwise open architecture. It almost worked.
This is where Lotus 1-2-3 enters the story. Written in x86 assembly, Lotus bypassed the BIOS for direct screen access and was co-optimized with the IBM PC’s hardware architecture - the Intel 8088 chip, the CGA display, the specific memory layout. It was fast because it was tightly coupled to that hardware. And that coupling had a telling side effect: Lotus ran poorly on early PC clones that hadn’t fully reverse-engineered IBM’s BIOS. The software exposed the one remaining interdependent interface in the system. Clone makers had to get the BIOS exactly right before Lotus would run which meant before the clone could be sold to a business. Interdependence and compatibility made visible.
This is the first lesson: in an interdependent system, pricing power flows to whoever controls the critical interfaces. IBM’s mainframes were expensive because IBM controlled every interface. The PC began the transition away from that, but the residual interdependence in the BIOS kept the price of full compatibility high until Compaq, Columbia, and others cracked it.
The Transition: When Good Enough Unlocks Modularization
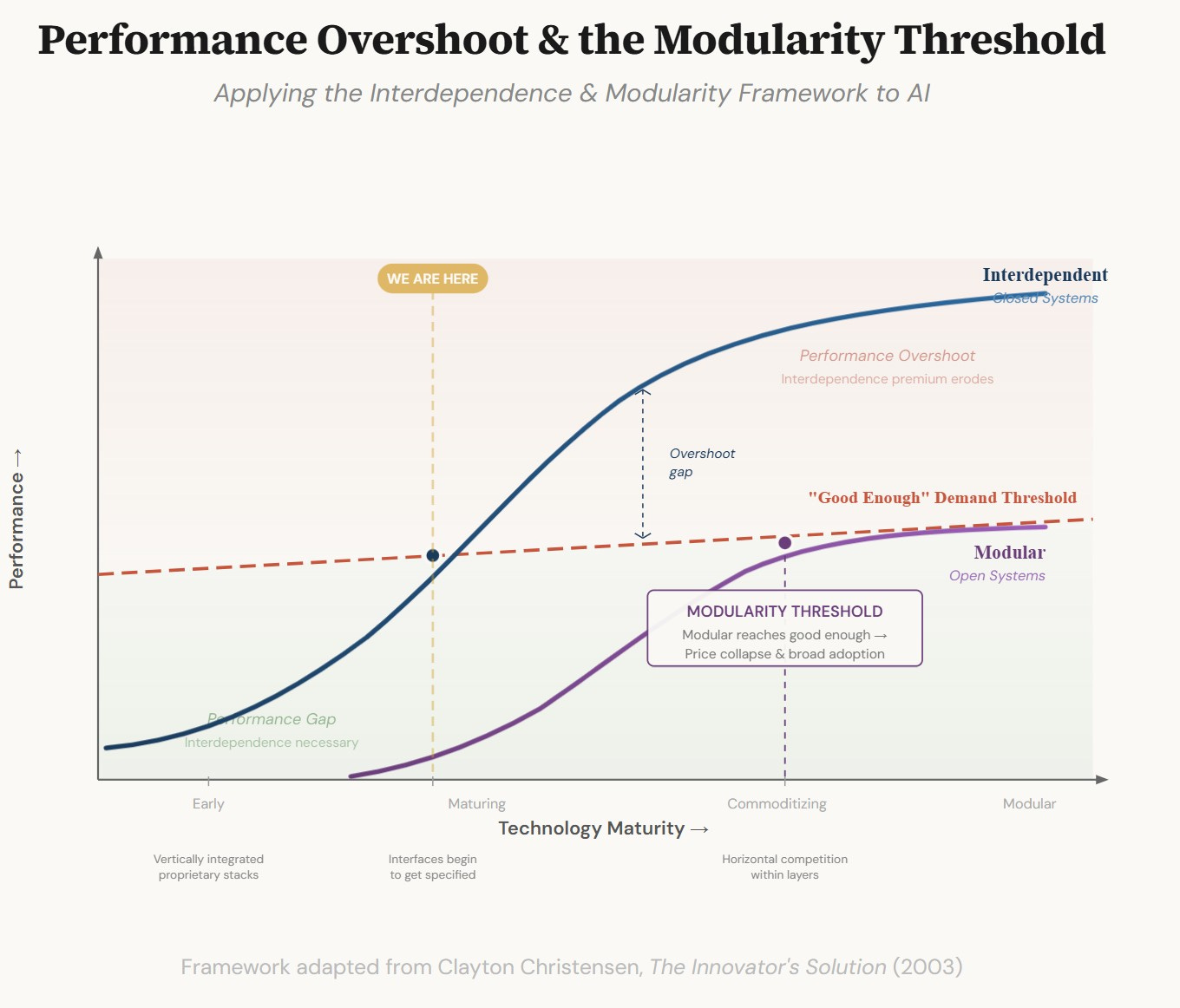
Christensen’s theory predicts what happens next. As the technology matures, performance crosses a threshold and it becomes good enough for most users. At that point, the basis of competition shifts. Users stop asking “does it work well enough?” and start asking “can I get it cheaper, more conveniently, customized for my specific need?” The performance premium of interdependence no longer justifies its cost.
This is the moment when modularization becomes possible, and when it becomes inevitable.
With the IBM PC, that moment arrived faster than IBM expected. Compaq reverse-engineered the BIOS legally through clean-room engineering. Columbia Data Products followed. Once the last proprietary interface fell, the architecture was fully open and what happened next was the full disintegration of the PC supply chain into competing horizontal layers. Microsoft owned the operating system. Intel owned the microprocessor. Seagate, Conner Peripherals, Western Digital and 100 other companies competed ferociously on hard drives. Korean and Japanese manufacturers commoditized DRAM. Taiwanese contract manufacturers - Quanta, Foxconn, Compal assembled the whole thing for razor-thin margins. Taiwan Semiconductor Manufacturing Company, founded in 1987, introduced the pure-play foundry model, allowing fabless chip designers to exist without building their own factories (which was critical for interface, multimedia and other I/O chips.
Each layer now competed against other companies in the same layer, with standardized interfaces between layers. A 256-kilobit RAM chip that sold for $8.95 in January 1985 cost $2.95 by September of the same year a 67% drop in nine months because the interface between memory and motherboard was now a standard specification. From 1982 to 1992, PC unit prices fell from around $3,000 to under $1,000. By the mid-1990s, nearly every PC in America was a clone, and the clone was cheap enough to put on every desk.
The modularity unlocked the disintegration. The disintegration drove the price collapse. The price collapse created the productivity revolution.
Christensen’s observation about Dell is the clearest illustration: once the PC’s architecture was modular, Michael Dell could go into a dorm room and assemble a competitive computer from components made by different companies. He just needed one of each part. The interfaces were specified. The value had been driven down to nearly zero at the assembly layer. Dell won not by building better computers but by building a better supply chain for modular components.
The Wrong Debate
I’ve been watching a discussion unfold in technology circles about AI adoption that I think is asking the wrong question.
The trend, dubbed “token maxxing” by some observers, casts the challenge as one of consumption; how to use more AI, how to integrate it into more workflows, how to maximize the tokens your organization burns. Some managers are apparently evaluating employees partly by AI token consumption, the theory being that heavy usage signals transformation.
That’s the wrong way to think about it for long term AI gain. It treats AI adoption as an intensity problem when the real problem is one of access and cost.
The question that matters isn’t how many tokens your power users are burning. It’s whether AI has reached the modularity threshold to drive adoption and right now, it hasn’t.
AI Is Deeply Interdependent. Necessarily So.
Today’s frontier AI systems are as interdependent as IBM’s mainframes - and for the same reason. Performance is not yet good enough to sacrifice the benefits of tight integration.
The training infrastructure, the model architecture, the inference optimization, the safety tuning, the RLHF process, the system prompt design, the tool-use interfaces are all deeply co-engineered. Changing one affects the others in ways that are not fully predictable. Anthropic cannot simply hand its inference layer to a commodity provider without losing or breaking something. OpenAI cannot separate its fine-tuning pipeline from its base model training without accepting a performance penalty. The interfaces are not fully specified. The architecture is not modular.
This is not a strategy to protect pricing power, though it has that effect. It is the engineering reality of a technology that is not yet good enough to accept the performance costs of modularization. The technology interdependence is necessary - for now.
The Token Cost Paradox
The cost of tokens (and how they are changing) is encouraging on the surface. Frontier model prices have fallen from roughly $10 per million tokens in 2023 to around $2.50 by early 2025; a 75% drop in a single year. Andreessen Horowitz has coined the term “LLMflation” to describe this deflationary curve, drawing an explicit parallel to Moore’s Law.
The models that are getting dramatically cheaper are yesterday’s models. However, the frontier state-of-the-art reasoning systems that are transforming complex knowledge work is holding its pricing relatively steady. When a new frontier model arrives, demand floods toward it immediately. This creates a treadmill: prices fall, but capability appetite rises faster. Until it doesn’t. I believe that we are starting the see signs of “good enough” model performance for some tasks, but not enough of them.
This is important because the problem is structural. Agentic AI systems that plan, use tools, search for information, check their own work, and iterate across multiple steps consume 10x to 100x more tokens per task than a simple prompt. The per-task cost of meaningful AI work has not followed the per-token headline down.
What’s more troubling is that the current economics are partly a subsidy. The hyperscalers and model builders - Anthropic, OpenAI, Google - are racing to capture market share partly by pricing below the true cost of inference. Alphabet alone is projected to spend $175 to $185 billion on AI infrastructure in 2026, nearly double the prior year. These are the spending patterns of a land grab, not a mature business. When investors demand margin discipline, pricing strategies will face upward pressure as businesses are trying to deepen AI integration.
Modularity Has to Come Before Disintegration Can Save Us
Here is the sequence that the PC industry followed, and that AI needs to achieve to see more broad adoption:
1) AI performance crosses the good enough threshold. The technology does what most users need it to do. At this point the interdependence premium starts to erode; you don’t need the tightest possible integration anymore because “tight enough” is sufficient.
2) Interfaces get specified. Someone (or the market collectively) defines what the standard handoffs between layers look like. In the PC, this was the ISA bus specification, the DOS API, the x86 instruction set. These weren’t accidents. They were the result of market pressure, open publication, and reverse engineering forcing interfaces into the open.
3) Modularization enables competition within layers. Once the interfaces are specified, companies can compete on individual layers without controlling the whole stack. Hard drive makers race each other. Memory manufacturers race each other. Assemblers race each other. Value concentrates where interfaces remain proprietary or where innovation is still unpredictable; which is why Intel and Microsoft made fortunes while PC assemblers scraped for margin.
4) Disintegration and modularity drive the price collapse. As competing horizontal layers commoditize elements that can be commoditized.
AI is currently between steps one and two. Performance has crossed good-enough for many applications; the basic reasoning, writing, and summarization tasks that most knowledge workers would benefit from. Sadly, the fact that this is happening might be too subtle for the average employee. The need to use the “latest model” is expensive and at times overkill. However, even for these earlier models, the interfaces are not yet specified. There is no standard for how an inference provider hands off to a memory layer, or how a fine-tuning service talks to a base model, or how an agentic orchestration framework interacts with tool-use APIs across different providers. Every major AI provider uses proprietary interfaces that lock users into their stack; not because they are malicious, but because the architecture just isn’t modular yet.
The open models, Llama, Mistral, DeepSeek are the beginning of interface specification. They are establishing what a capable base model looks like as a standard component that others can build on. That is the equivalent of the x86 instruction set becoming the baseline that everyone in the industry assumed. But base model standardization is only one interface. The full stack has many more that need to be considered.
The Emerging Modular Layers
The modular interfaces are beginning to form, and you can see them if you know where to look.
The most concrete example is happening right now. In late 2024, Anthropic released the Model Context Protocol ”MCP” as an open standard for how AI models connect to external tools, data sources, and services. Before MCP, every AI application had to build its own bespoke integrations: a model talking to a database, a calendar, or a code repository all required custom connectors built from scratch. That is textbook interdependence as the interface between model and tool was proprietary and had to be rebuilt for every combination. MCP specifies that interface as a standard. Any tool that implements MCP can talk to any model that implements MCP, without custom integration work. It is the USB port of AI or more precisely, it is the ISA bus moment for the agent-to-tool layer. Once IBM published the PC’s expansion slot specification, dozens of companies could build compatible cards without asking IBM’s permission. MCP does the same thing for AI tools.
Then in April 2025, Google released the Agent-to-Agent protocol ”A2A”, co-developed with over fifty industry partners, and now governed by the Linux Foundation. Where MCP is vertical (a model talking down to a tool), A2A is horizontal: it specifies how autonomous AI agents talk to each other, delegate tasks, and collaborate across different vendors and frameworks. An agent built by one company can now discover, communicate with, and hand off work to an agent built by another without custom integration. AWS has joined the MCP steering committee, signaling that the major cloud providers are treating these as infrastructure standards rather than competitive moats.
IBM, contributed the Agent Communication Protocol ”ACP” through the Linux Foundation, targeting cross-framework interoperability for enterprise agent deployments. Notably, the company that once controlled every interface in computing is now helping specify open standards for AI agents.
Three protocols, each addressing a different interface layer, all arriving within eighteen months of each other. This is the interface specification phase beginning in earnest - but it is only one part of the stack. The model-to-inference-hardware interface remains largely proprietary. The fine-tuned model interoperability layer doesn’t yet exist as a standard. The base-model-to-training-pipeline interface is entirely controlled by individual providers. Those gaps are where the interdependence premium still concentrates, and where pricing power still sits.
The inference layer is also beginning to separate from the model layer. Companies like Groq and Cerebras are building inference hardware optimized to run existing models faster and cheaper than general-purpose GPU clusters, the equivalent of specialized hard drive manufacturers who competed storage costs down independently of whoever designed the PC if they supported a standard interface. New inference hardware can do this because the interface between a model and its inference hardware is increasingly specifiable.
Distillation and fine-tuning are creating a layer between frontier models and deployed applications. A fine-tuned smaller model for a specific legal workflow, trained on top of an open-weight base, is a modular component, it has a defined interface (the task it performs), it can be produced by specialists, and it can be replaced when something better arrives. This is the application-specific (ASIC) chip equivalent: you don’t need Intel’s full general-purpose CPU if a specialized processor does your job for a tenth of the cost. Adaptec and Cirrus Logic made nice businesses out of this in the PC era.
Each of these is the beginning of a horizontal layer that can compete independently. Each one, as its interfaces get specified, will drive prices down within that layer. The full disintegration of the AI supply chain - the event that will drive costs low enough for broad deployment depends on these interfaces becoming standard.
If the Price Wall Holds
The productivity gap is already forming.
Large enterprises adopt AI at roughly three times the rate of small businesses. For example, in the United Kingdom, 52% of large firms report active AI deployment versus 17% of small ones, a 35-point gap that has persisted stubbornly. The early productivity gains being reported are real, but they are being captured overwhelmingly by organizations with the budgets and IT infrastructure to absorb the cost of genuine deployment. This is not a technology gap. A five-person accounting firm can access the same Claude or GPT-4 that Goldman Sachs uses. The gap is economic and architectural: Anthropic, OpenAI, and Google are vertically integrated in much the way IBM’s mainframe division was, they control the full stack, the interfaces are proprietary, and pricing power flows from that control. The open-weight models and inference specialists are playing the role of the IBM PC; the modular disruption arriving from below. But unlike the IBM PC, which accidentally opened its architecture under deadline pressure, AI’s modular transition will have to be forced by market competition and the gradual specification of standard interfaces.
This is the 1983 problem. The tool exists. The price, and the integration complexity that comes with interdependence, is the barrier.
If the modularity transition is slow, if AI providers successfully maintain proprietary interfaces and resist the specification of standard handoffs, the disintegration of AI will be delayed. The price collapse will be delayed. Therefore, the productivity revolution will remain concentrated among the organizations that could afford to deploy during the interdependent, expensive phase.
The current subsidy window makes this urgent. If the hyperscaler land grab ends and if capital markets demand that Anthropic, OpenAI, and Google demonstrate margin discipline - prices could rise right when the modular alternatives are still immature. The window between “subsidized interdependent AI” and “commoditized modular AI” is where the access gap either closes or materially widens.
What Has to Happen
AI needs to cross the good-enough threshold for a wide enough range of workflows that the performance premium of tight integration starts to erode, and customers need to recognize this change. Token costs might be what “opens their eyes”. The reality is that for many tasks “older” models are good enough. For the reasoning-heavy, high-stakes applications that enterprises care most about, AI is not is not yet “good enough” which is why frontier models still command premium pricing and why the interdependence premium persists.
As good-enough spreads across more use cases, the pressure to specify interfaces will intensify. Open-weight models are the leading edge of this. Every time a fine-tuned Llama model matches a proprietary frontier model on a specific task, that interface becomes specifiable: “a model that does X” is now a commodity slot in the stack, not a locked-in vendor relationship.
The disintegration will follow. It will look like the PC supply chain: specialized inference hardware, commodity model hosting, a market for fine-tuned vertical models, application-layer assembly by a Dell-equivalent who just plugs together standard components. The smiling curve will reassert itself; value concentrating at the research frontier and at the application layer, with the commodity middle approaching free.
The question is not whether this happens. The structural incentives are identical to the ones that pulled apart the PC industry, and markets are very good at following structural incentives. The question is when, and whether “when” is soon enough to matter for the millions of small businesses and non-elite workers who need this technology to be cheap for productivity gain.
Watch the Interfaces
The spreadsheet changed the world. The clone cracked the door. The supply chain disintegration blew it open; but only because the PC’s architecture had become modular enough that disintegration was possible.
The clone makers for AI already exist. The open-weight models, the inference specialists, the orchestration frameworks - they are playing the Compaq and Dell role. But Dell and Compaq alone didn’t create the PC productivity revolution. It was the full stack: the specified interfaces that let hard drive makers compete against hard drive makers, and memory makers against memory makers, and assemblers against assemblers, all the way down to the $599 Dell that a small business could buy without a CFO conversation.
AI needs that full stack. And the full stack needs modularity first.
MCP and A2A are the first “component interfaces” getting specified; the agent-to-tool and agent-to-agent layers beginning to standardize. When the inference-to-model interface follows, when fine-tuned vertical models can be swapped in and out like hard drives, when the full stack has specified handoffs at every layer - that is when the disintegration accelerates, the price collapses, and the productivity revolution reaches everyone.
We are not there yet. But it’s coming. The spreadsheet changed the world. The clone made it possible. The supply chain made it universal.
We’re still waiting for the modular supply chain.
Crawford Del Prete is a Senior Advisor at PSG Equity and former President of IDC. He writes about enterprise software, AI, and technology market dynamics. All opinions are his.
Excellent post!
My two cents and some of the following will overlap with your post: I found the PC analogy useful, especially the focus on modularity and interface standardization. However, I think the argument may understate a critical difference between PCs and AI: even if AI becomes cheaper and more modular, that alone may not produce enterprise productivity gains unless work, systems, and users are redesigned around it. AI’s bottleneck is not only cost or architecture; it is organizational capability.
First, I’m not convinced today’s AI products are “good enough” to deliver broad productivity gains for non-expert users. Yes, they can write and summarize, but what I am seeing in most organizations, including my own, is that the outputs are often generic unless users provide strong context, ask precise questions, and have enough expertise to evaluate the result. In practice, AI currently seems to amplify skilled workers more reliably than it substitutes for skill. If the average employee needs to become an expert prompt designer and reviewer, adoption will be much narrower than the PC analogy implies.
Second, the cost structure feels meaningfully different. A PC was expensive up front, but once purchased, the marginal cost of use was low. AI is closer to a metered utility: every prompt, agentic loop, retrieval step, tool call, and validation pass consumes compute. The relevant metric is not cost per token, but cost per completed business task, including integration, review, compliance, monitoring, and error correction. Even with modularity, the core infrastructure for frontier training and inference may remain capital-intensive and concentrated among a few providers.
Third, AI components are not interchangeable in the same way PC components were. A hard drive that met the interface spec generally worked as expected. Two models can expose the same API and yet behave very differently in terms of accuracy, reasoning, hallucination rate, refusal behavior, tool use, and formatting discipline. So standardized interfaces like MCP or A2A are necessary, but not sufficient. AI also needs evaluation standards, behavioral guarantees, auditability, and reliability layers before enterprises can treat components as truly swappable.
Fourth, nondeterminism creates a major barrier to critical workflows. Many enterprise processes require repeatability, accountability, compliance, and clear failure modes. AI can help draft, classify, summarize, and recommend, but in high-stakes workflows, it still needs deterministic controls and expert human review. If every meaningful use case requires expert validation, the productivity gain depends heavily on whether the system saves more expert time than it consumes.
Finally, and most importantly, enterprise productivity requires organizational redesign. Giving everyone a chatbot is not the same as transforming work. Without redesigning business processes, data flows, approval chains, systems of record, incentives, and human roles around AI, productivity gains will remain limited. Many organizations will add AI on top of existing workflows and get incremental improvements, generic content, or more review burden.
So I agree that modularity and lower costs matter. But I’d argue they are necessary rather than sufficient. For AI to deliver PC-scale productivity gains, we also need context infrastructure, evaluation layers, deterministic controls, data governance, redesigned business processes, and users who are trained to work effectively with AI. Otherwise, the benefits may remain concentrated among experts and large enterprises with the organizational capability to absorb the complexity.
Thanks for breaking down the pieces. Fond memories of life in the 80’s. One thing feels a little different about AI vs PCs: Michael Dell could build PC’s from his dorm room, but the massive capital required for inference capacity limits the competition at the foundational level. AI feels more like railroads and electric power companies where you got standards but at some point while margins compressed, the market leveled out to a few providers with guaranteed but constrained margins. That doesn’t change the point about where value will be created elsewhere in the supply chain as you’ve pointed out. There may have been a limited number of power companies, but they enabled lots of appliance manufacturers.